Consider a ride-sharing application that experiences varying levels of user activity throughout the day. To efficiently handle the fluctuating demand and ensure seamless user experiences, the application leverages serverless computing in its cloud environment:
- Scenario: A ride-sharing application with varying levels of user activity.
- Architecture design: The application is designed using a serverless architecture. Instead of provisioning and managing traditional virtual machines or containers, the application consists of individual serverless functions.
- Function deployment: Different functions are created to handle various aspects of the application, such as user authentication, ride booking, and driver matching.
- Event-driven scaling: The serverless functions are event-driven, meaning they are invoked in response to specific events, such as user requests.
- Scaling mechanism: When user activity is low, only a few serverless functions are active. As the number of user requests increases, the serverless platform automatically scales out by deploying additional instances of the functions.
- Resource allocation: Each function instance is allocated resources (CPU, memory, and so on) on demand. The cloud provider manages the resource allocation process, ensuring optimal performance and resource utilization.
- Peak periods: During peak hours, such as rush hour or weekends, the application experiences a surge in ride requests.
- Dynamic scaling: The serverless platform detects the increase in incoming events and scales out by launching multiple instances of the functions to handle the higher load.
- Load balancing: Incoming requests are distributed across the available function instances through load balancing, ensuring even distribution of traffic.
- Auto-scaling: As the demand decreases during non-peak hours, the serverless platform scales in by reducing the number of function instances.
- Benefits and insights:
• Cost optimization: The application pays only for the actual compute time and resources used by the functions, leading to cost savings during periods of low activity
• High scalability: The serverless architecture allows the application to scale effortlessly in response to spikes in user demand, ensuring consistent performance
• Automatic management: The cloud provider handles the underlying infrastructure, allowing the application developers to focus solely on writing code
• Resilience: The application’s auto-scaling capabilities make it resilient to sudden traffic spikes, preventing performance bottlenecks or downtimes
• Efficient resource utilization: Serverless functions are only active when invoked, making efficient use of resources and reducing waste
This real-world example showcases how serverless computing provides an ideal solution for applications with unpredictable workloads. By automatically scaling resources based on event-driven triggers, the application can provide optimal performance and cost-efficiency, even during varying levels of user activity.
Various cloud providers offer tools and services to facilitate efficient resource utilization and scaling. Let’s take a quick look at the tools and services provided by different cloud vendors.
AWS:
• Auto Scaling: AWS Auto Scaling allows users to configure automatic scaling for multiple services, such as Amazon EC2 instances, Amazon ECS tasks, and more. It uses predefined scaling policies or custom metrics to adjust resources based on demand. The following figure depicts how to autoscale EC2 compute instances in AWS. Here, T3 is the EC2 compute instance type, which receives connections through the Elastic Load Balancer:
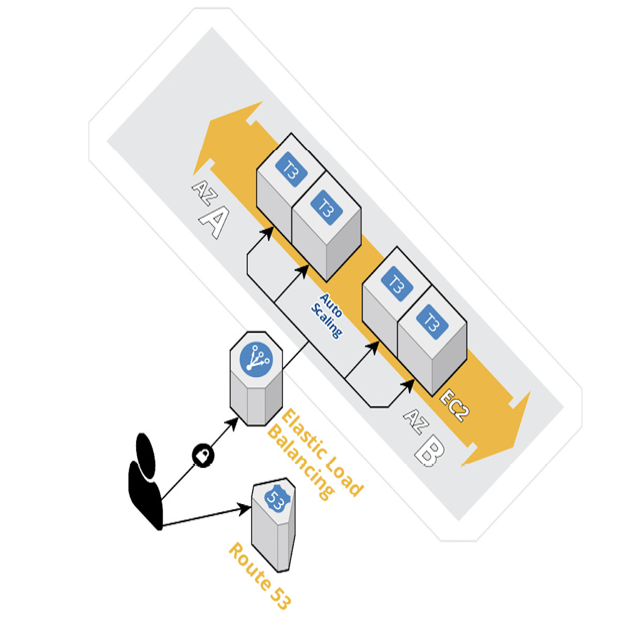
Figure 10.2: Autoscaling in AWS cloud
• ELB: AWS ELB distributes incoming traffic across multiple instances, ensuring availability and fault tolerance. It includes Application Load Balancers (ALBs) and Network Load Balancers (NLBs).
• Amazon EC2 Auto Scaling: This service automatically adjusts the number of EC2 instances in a scaling group based on conditions defined by the user. It helps maintain application availability and allows scaling in and out.